1. Adding A New redo log Group
1
| sql> ALTER DATABASE ADD LOGFILE('/oracledata/test/redo3a.log','/test_multiplex/redo3b.log') SIZE 52429312; |
1
| sql> ALTER DATABASE ADD LOGFILE THREAD 1 GROUP 15 ('/oracledata/test/redo3a.log','/test_multiplex/redo3b.log') SIZE 52429312; |
1
| sql> ALTER DATABASE ADD LOGFILE THREAD 1 GROUP 15 ('/oracledata/test/redo3a.log','/test_multiplex/redo3b.log') SIZE 52429312; |
Before dropping a redo log group, make sure that at the moment, logwriter process is not writing to the redo log file you plan to drop.
1
| sql> SELECT GROUP#, THREAD#,ARCHIVED, STATUS FROM V$LOG ; |
| GROUP# | THREAD# | ARC | STATUS |
|---|---|---|---|
| 1 | 1 | YES | INACTIVE |
| 2 | 1 | NO | CURRENT |
| 3 | 1 | YES | INACTIVE |
If the status is "CURRENT" it means that logwriter is currently using this group to store redo records. After the redo files in this group is filled it will switch to next group. You may wait till next log switch operation or you may manually trigger it by command below:
1
| SQL> alter system switch logfile ; |
1
| sql> alter system checkpoint ; |
1
| sql> ALTER DATABASE DROP LOGFILE GROUP 6; |
Logwriter writes to redo log files in a circular fashion. When a group is filled it moves to next group. After all groups in database are filled it returns back to first redo log group. Because of that, there has to be at least 2 groups in an instance. Oracle won't permit dropping a group if there are only two groups in the instance.
After dropping a group, you may delete relevant files from operating system.
3. Adding A New Member To An Existing Group
As mentioned at the beginning of article it is recommended to multiplex redo log members for fault tolerance. You can accomplish this by adding new members to an existing group.
1
| sql> ALTER DATABASE ADD LOGFILE MEMBER '/u02/oradata/mydb/redo02.log' TO GROUP 2; |
4. Dropping A Member From An Existing Group
As stated in subject 3 (Dropping A redo log Group) again the group, whose member you want to drop should be inactive.
1
| sql> ALTER DATABASE DROP LOGFILE MEMBER '/u03/oradata/mydb/redo03.log' |
You may want to relocate your existing redo log group and change the path of redo log files. Here are the steps to accomplish it
Step 1: Shutdown database
1
| sql> shutdown immediate ; |
Step 3: Move your redo log member to a new location. You may also change the file name if you want.
1
| # mv /u02/oradata/mydb/redo02.log /u03/oradata/mydb/redo03.log |
1
| sql> startup nomount; |
1
| sql> ALTER DATABASE RENAME FILE '/u02/oradata/mydb/redo02.log' TO '/u03/oradata/mydb/redo03.log' |
1
| sql> alter database open; |
*****************************************************************
Yesterday we found and realized that there has been too much log switching in one of our databases and it was impacting the database performance. This excessive log switching was happening because our Redo Log files were not enough large as per the the database activity.
We had 50 MB Redo Log Files, 1 Redo Thread, 2 Redo Log Groups and One member in each group.
We decided to increase the Redo Log size to 100MB.
The Redo Logs must be dropped and recreated for changing the redo log size. It can be done online without shutting down the database. However, you need to make sure that the Redo Group being dropped should be INACTIVE when you do this.
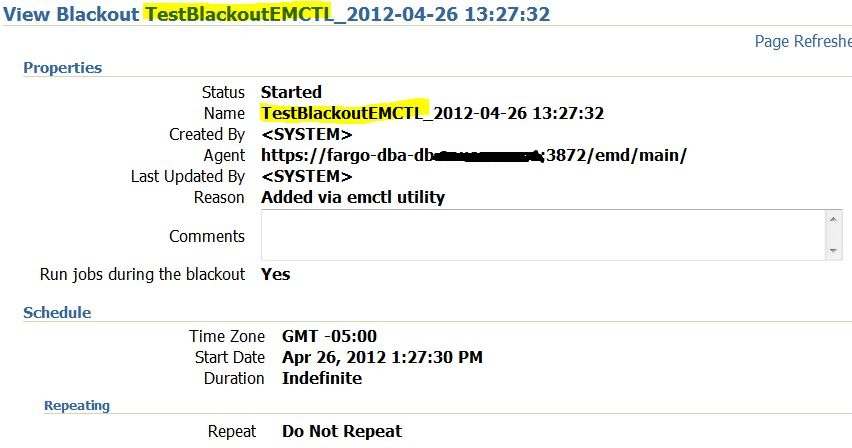
We have the following Log Groups and members:
SQL> select * from v$logfile; GROUP# STATUS TYPE MEMBER IS_RECOVE ---------- --------------------- --------------------- ------------------------------------------------------------ --------- 2 ONLINE /app01/oratest/oradata/BOTI/BOTI/redo02.log NO 1 ONLINE /app01/oratest/oradata/BOTI/BOTI/redo01.log NOAnd the status of the Log Groups is:
SQL> select * from v$log; GROUP# THREAD# SEQUENCE# BYTES MEMBERS ARCHIVED STATUS FIRST_CHANGE# FIRST_TIME ---------- ---------- ---------- ---------- ---------- --------- ------------------------------------------------ ------------- --------------- 1 1 12 52428800 1 NO CURRENT 1156736 27-JAN-11 2 1 11 52428800 1 YES ACTIVE 1156732 27-JAN-11Here we see that the Group# 1 is being used Currently and the Group# 2 though not being used Currently, however is ACTIVE (means if the Database crashes now, you will need this Group for recovery.) We need to make this group Inactive before proceeding ahead:
For this, execute a checkpoint:
SQL> alter system checkpoint; System altered.Now again check the status of the Redo Groups:
SQL> select * from v$log; GROUP# THREAD# SEQUENCE# BYTES MEMBERS ARCHIVED STATUS FIRST_CHANGE# FIRST_TIME ---------- ---------- ---------- ---------- ---------- --------- ------------------------------------------------ ------------- --------------- 1 1 12 52428800 1 NO CURRENT 1156736 27-JAN-11 2 1 11 52428800 1 YES INACTIVE 1156732 27-JAN-11The group 2 is now Inactive. Hence we can proceed with dropping this group:
SQL> alter database drop logfile group 2; alter database drop logfile group 2 * ERROR at line 1: ORA-01567: dropping log 2 would leave less than 2 log files for instance BOTI (thread 1) ORA-00312: online log 2 thread 1: '/app01/oratest/oradata/BOTI/BOTI/redo02.log'What went wrong ???
It’s a basic requirement in Oracle Database that there should always be a minimum 2 Redo Log Groups available with the Database. Hence we can not drop any Redo Group if there are only 2 Groups.
To overcome this issue, we need to add one more Redo group to the database.
Execute the following step:
SQL> alter database add logfile group 3 '/app01/oratest/oradata/BOTI/BOTI/redo03.log' size 100M; Database altered.Now check the logfiles:
SQL> select * from v$logfile; GROUP# STATUS TYPE MEMBER IS_RECOVE ---------- --------------------- --------------------- ------------------------------------------------------------ --------- 3 ONLINE /app01/oratest/oradata/BOTI/BOTI/redo03.log NO 2 ONLINE /app01/oratest/oradata/BOTI/BOTI/redo02.log NO 1 ONLINE /app01/oratest/oradata/BOTI/BOTI/redo01.log NO… and the status of the Groups:
SQL> select * from v$log; GROUP# THREAD# SEQUENCE# BYTES MEMBERS ARCHIVED STATUS FIRST_CHANGE# FIRST_TIME ---------- ---------- ---------- ---------- ---------- --------- ------------------------------------------------ ------------- --------------- 1 1 12 52428800 1 NO CURRENT 1156736 27-JAN-11 2 1 11 52428800 1 YES INACTIVE 1156732 27-JAN-11 3 1 0 104857600 1 YES UNUSED 0The status of the new Group is UNUSED because it has never been used.
Now, we have 3 Redo Groups in our database. We can now proceed with Dropping Redo Group# 2.
SQL> alter database drop logfile group 2; Database altered.Also, delete the file ‘/app01/oratest/oradata/BOTI/BOTI/redo02.log’ from File system also.
Now add the Redo Group 2 back to the database with changed Redo size:
SQL> alter database add logfile group 2 '/app01/oratest/oradata/BOTI/BOTI/redo02.log' size 100M; Database altered. SQL> select * from v$logfile; GROUP# STATUS TYPE MEMBER IS_RECOVE ---------- --------------------- --------------------- ------------------------------------------------------------ --------- 3 ONLINE /app01/oratest/oradata/BOTI/BOTI/redo03.log NO 2 ONLINE /app01/oratest/oradata/BOTI/BOTI/redo02.log NO 1 ONLINE /app01/oratest/oradata/BOTI/BOTI/redo01.log NO SQL> select * from v$log; GROUP# THREAD# SEQUENCE# BYTES MEMBERS ARCHIVED STATUS FIRST_CHANGE# FIRST_TIME ---------- ---------- ---------- ---------- ---------- --------- ------------------------------------------------ ------------- --------------- 1 1 12 52428800 1 NO CURRENT 1156736 27-JAN-11 2 1 0 104857600 1 YES UNUSED 0 3 1 0 104857600 1 YES UNUSED 0Now we have to drop the 1st Redo Log Group. Before that, we need to change the status of this group:
SQL> alter system switch logfile; System altered. SQL> select * from v$log; GROUP# THREAD# SEQUENCE# BYTES MEMBERS ARCHIVED STATUS FIRST_CHANGE# FIRST_TIME ---------- ---------- ---------- ---------- ---------- --------- ------------------------------------------------ ------------- --------------- 1 1 12 52428800 1 YES ACTIVE 1156736 27-JAN-11 2 1 13 104857600 1 NO CURRENT 1157376 27-JAN-11 3 1 0 104857600 1 YES UNUSED 0Still the Grpoup is in Active status. Issue a checkpoint:
SQL> alter system checkpoint; System altered. SQL> select * from v$log; GROUP# THREAD# SEQUENCE# BYTES MEMBERS ARCHIVED STATUS FIRST_CHANGE# FIRST_TIME ---------- ---------- ---------- ---------- ---------- --------- ------------------------------------------------ ------------- --------------- 1 1 12 52428800 1 YES INACTIVE 1156736 27-JAN-11 2 1 13 104857600 1 NO CURRENT 1157376 27-JAN-11 3 1 0 104857600 1 YES UNUSED 0Now we can drop the Redo Group# 1.
SQL> alter database drop logfile group 1; Database altered. SQL> select * from v$log; GROUP# THREAD# SEQUENCE# BYTES MEMBERS ARCHIVED STATUS FIRST_CHANGE# FIRST_TIME ---------- ---------- ---------- ---------- ---------- --------- ------------------------------------------------ ------------- --------------- 2 1 13 104857600 1 NO CURRENT 1157376 27-JAN-11 3 1 0 104857600 1 YES UNUSED 0 SQL> select * from v$logfile; GROUP# STATUS TYPE MEMBER IS_RECOVE ---------- --------------------- --------------------- ------------------------------------------------------------ --------- 3 ONLINE /app01/oratest/oradata/BOTI/BOTI/redo03.log NO 2 ONLINE /app01/oratest/oradata/BOTI/BOTI/redo02.log NODelete the file ‘/app01/oratest/oradata/BOTI/BOTI/redo01.log’ from OS.
Now we need to add this group back to the database with 100MB Redo Log file:
SQL> alter database add logfile group 1 '/app01/oratest/oradata/BOTI/BOTI/redo01.log' size 100M; Database altered. SQL> select * from v$log; GROUP# THREAD# SEQUENCE# BYTES MEMBERS ARCHIVED STATUS FIRST_CHANGE# FIRST_TIME ---------- ---------- ---------- ---------- ---------- --------- ------------------------------------------------ ------------- --------------- 1 1 0 104857600 1 YES UNUSED 0 2 1 13 104857600 1 NO CURRENT 1157376 27-JAN-11 3 1 0 104857600 1 YES UNUSED 0Here we can see that all the Redo Groups are now showing 100MB size (column BYTES).
SQL> select * from v$logfile; GROUP# STATUS TYPE MEMBER IS_RECOVE ---------- --------------------- --------------------- ------------------------------------------------------------ --------- 3 ONLINE /app01/oratest/oradata/BOTI/BOTI/redo03.log NO 2 ONLINE /app01/oratest/oradata/BOTI/BOTI/redo02.log NO 1 ONLINE /app01/oratest/oradata/BOTI/BOTI/redo01.log NOThough it’s suggested that you should keep 3 groups, if you want you can drop the Redo Group 3 which we added for this exercise.
SQL> alter database drop logfile group 3; Database altered. SQL> select * from v$logfile; GROUP# STATUS TYPE MEMBER IS_RECOVE ---------- --------------------- --------------------- ------------------------------------------------------------ --------- 2 ONLINE /app01/oratest/oradata/BOTI/BOTI/redo02.log NO 1 ONLINE /app01/oratest/oradata/BOTI/BOTI/redo01.log NO SQL> select * from v$log; GROUP# THREAD# SEQUENCE# BYTES MEMBERS ARCHIVED STATUS FIRST_CHANGE# FIRST_TIME ---------- ---------- ---------- ---------- ---------- --------- ------------------------------------------------ ------------- --------------- 1 1 0 104857600 1 YES UNUSED 0 2 1 13 104857600 1 NO CURRENT 1157376 27-JAN-11 SQL> alter system switch logfile; System altered. SQL> select * from v$log; GROUP# THREAD# SEQUENCE# BYTES MEMBERS ARCHIVED STATUS FIRST_CHANGE# FIRST_TIME ---------- ---------- ---------- ---------- ---------- --------- ------------------------------------------------ ------------- --------------- 1 1 14 104857600 1 NO CURRENT 1157584 27-JAN-11 2 1 13 104857600 1 YES ACTIVE 1157376 27-JAN-11
You have changed the Redo Log file size from 50M to 100M.




![[clip_image002[7].jpg]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiQ_Hh9nszGoD-K0nVeh_7z2GxauOLl7TXfaBxLAusaU-5xxVyJnEu9hBPaYfRw4IpuhX1llZddwNZrKKEnFODOR5Pvbnbe-OWQyFTlKS5KmjXBpFmetCn8CddtWaoOM9iOrlFz1efl7yY/s640/clip_image002%5B7%5D.jpg)
![[clip_image002[8][2].jpg]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhYYauC0qVmQ1DxFw0vAkLJIlAUZ96ABjMAvG0JnGl-4MqUBwFc8wNHBNqIiRBhdH_vFQbD1feKdB2zpzTXzKpxYxSL5cQNXv8id_AAxHLS7J0ZzOsDIaemoCCJ16D_RE_PoZT4yaD2dbY/s1600-h/clip_image002%5B8%5D%5B2%5D.jpg)
![[clip_image002[10][2].jpg]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhZnDDJ8oIWxwBXBY7-NZJZsJGgEQvZ3ey_qZ5XmLoutj507ZM2UVK1wF1o-DNsX-Nbg6MuLuMqo1Nf4MoVN3xkrmU-6X0ZZ5JeO-rfcte-QsITW317DTu4NZZtNCLQGmaDg6AiI9WlyJ8/s1600/clip_image002%5B10%5D%5B2%5D.jpg)
![[clip_image002[12][2].jpg]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgx7sADjO8gMvnJn2cdHuu_8apRnunzlIWzP6WXq0xoM2nY8vhpni843aFr0llpcwzt-auaB9EHEk0dmhnwVGP6HHSINhDgF8cfkzUSs9KWv9PNlvH-If4KGcecV_hW1Wq7y97rAAFHiO4/s1600-h/clip_image002%5B12%5D%5B2%5D.jpg)
![[clip_image002[14][2].jpg]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhRSs_u30dhrWgbt5C2u16UlvoCl4mRFrpyTPfUqBpj6jmtj2UVS7tJUOj4bC-y1tJcF1Tmep5yB9BZCGqD6fRw2omzJefkDA5KeEifADg2lsleQEujwn9Zl2qx01-PemeEC4Wntaxo4bI/s1600-h/clip_image002%5B14%5D%5B2%5D.jpg)

{kind=link}
{kind=link}
{kind=link}
{kind=link}